Novel Techniques - Curriculum Learning
02 Dec 2021 Table of ContentsIn Neural Network Optimization, most academics have moved on to more novel methods such as Deep Neural Nets and Cascading Networks. However, some techniques can be used to optimise more basic Simple Neural Networks that fall in line with Occam’s Razor. One of them is Curriculum Learning.
Brief
Occam’s razor, Ockham’s razor, Ocham’s razor (Latin: novacula Occami), also known as the principle of parsimony or the law of parsimony (Latin: lex parsimoniae), is the problem-solving principle that “entities should not be multiplied beyond necessity” - Our trusty pal Wikipedia
Tl;dr, Occam’s Razor basically says that creating complexity is usually unnecessary and sometimes detrimental to the performance of your system.
Tl;dr the Tl;dr: Simple is usually best.
In this case, Curriculum learning aims to improve model performance through a novel training technique that requires an empirical grading of your training data. After all, throwing things at a model and just expecting is to work seems like a very maddening way to get it to perform better (at least to me). This post will by no means be an exhaustive explication of the technique, for that please read one of the papers referenced at the end.
Understanding the Basics
Training a Neural Network usually involves:
- Data Preparation
- Training
- Evaluation
The latter 2 usually occurring over multiple iterations of the network with different hyperparameters. Curriculum Learning adds a step between 1 and 2 where the data is ‘graded’. There are many formulae that this grading system can use, but I’ll just be mentioning the simplest one here, what I call ‘student’ evaluations, where each set of inputs are graded based on how accurate the model is on it’s first or second pass.
The ‘Curriculum’
This excellent conceptual model of a the training process is from Kwon’s ‘Artificial Neural Networks’ book:
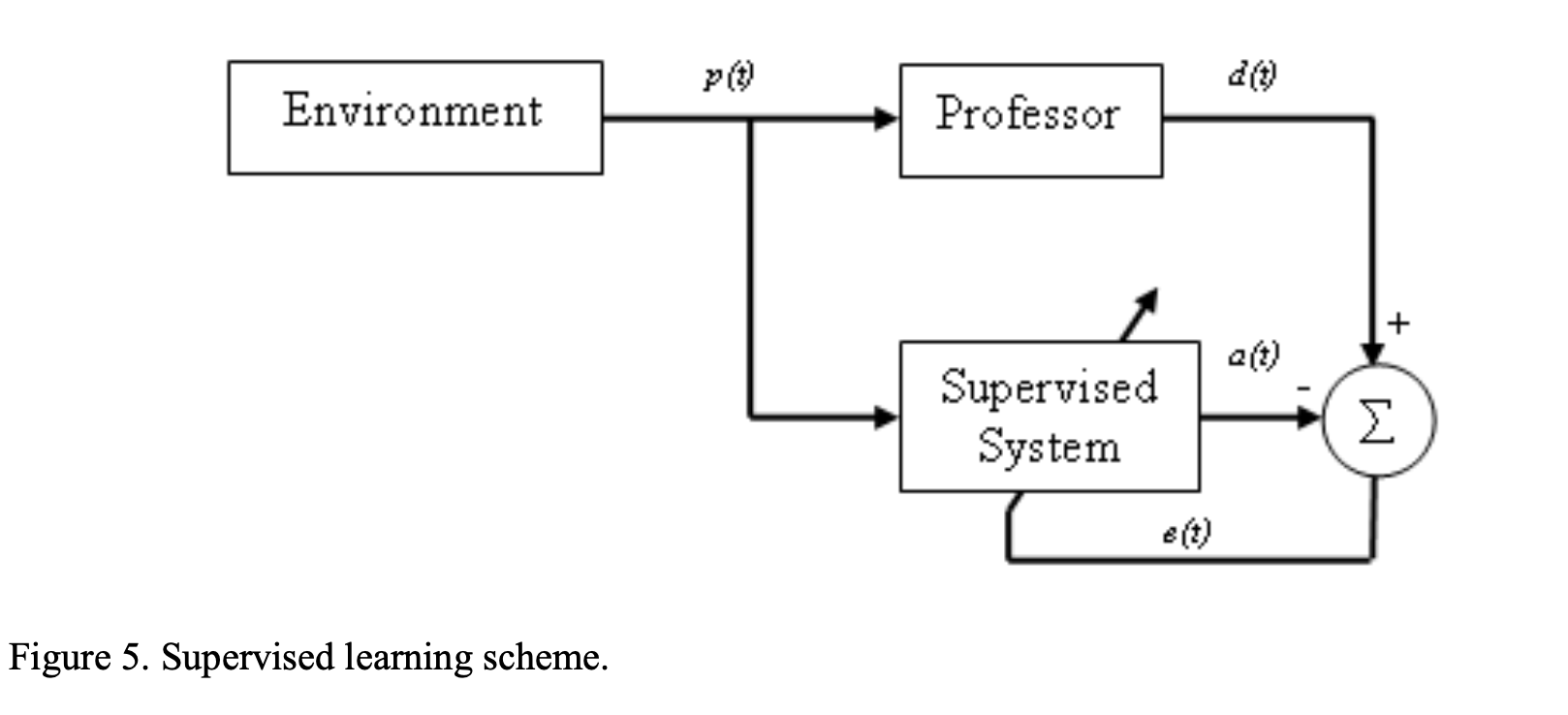
This process flow, while very basic, models the portion of the code that feeds in training data as a professor or teacher and the model is the student.
In Curriculum Learning, the professor simply creates a structured progression of ‘questions’ (essentially just sets of inputs) and ranks these into blocks segregated by difficulty. Difficulty can be determined by how well the model does on each input after a single (or negligibly few) run(s) with over formulae being proposed across various papers. Easy questions are asked first and after the student ‘gets the hang of those’, it moves on to progressively more difficult problems to solve.
This is basically a ‘path of least resistance’ and from my experiments, demonstrates a favorable and dramatic increase in performance. For a University Assignment, I had to create a classifier and demonstrate the affects of different training methods on performance, the full report can be seen here but long story short,
performance was boosted from an average a little above 86% to a steady mean of 97% (with a low standard deviation across runs for both models) even reaching 99% accuracy boasting very impressive lack of loss with (what I perceived to be) very little over-fitting.
Downsides
The first issue is the matter of grading. This requires some form of intimacy with the data before training and if the data is graded poorly or not properly split up, or if the training speed is too fast or too slow, it may have no effect. Thus we’ve introduced even more annoying hyperparameters to the mix.
The second issue makes the first one even more annoying. This method increases learning time significantly (and here ‘significantly’ is an understatement), which might not be feasible for larger models and make tuning much more tedious.
In Conclusion
This is a cool way (at least to me) to train NN’s and it has a lot of benefits, especially with smaller models. This might also give you a way to get out of a plateau that you may be facing with your model and we all know how annoying those can be. If you’re reading this, hope it helps!
References
- G. Hacohen and D. Weinshall, “On the power of curriculum learning in training deep networks,” 2019.
- Kwon SJ. Artificial Neural Networks. Nova Science Publishers, Inc; 2011. Accessed December 2, 2021.