Some Rules of Thumb for Complex Solutions and its' Management - Ideal Cone of Software
13 Sep 2024 Table of Contents- To be, or not to be…“complex”
- A Personal Glossary of Theoretical Relationships around Maintainability and Efficiency
- Enter Pseudo-Geometry - Rishi’s Ideal Cone of Software3
- TL;DR
Over my relatively short tenure as a software engineer so far, I’ve had a few thoughts on how to deal with “efficiency” and “maintainability” across multiple facets within my teams’ estate. It’s lead to a useful4 rule-of-thumb1 when trying to design/make decisions about systems in a way that balances efficiency and maintainability.
To be, or not to be…“complex”
The kick here, is that software is a team sport. You want things to be maintainable across the lifespan of the team not necessarily the individuals that happen to be within the team at the time of a decision.
Teams change over time. Knowledge gets lost with people. The solution never lies, but you might not be able to speak its language if you’ve lost the meaning of the words.
This is obviously a tall ask. If an answer to a design question seems apparent, I look at it with the utmost suspicion7. Maturing2 as an engineer has given me a couple of questions that I feel I need to consistently ask when thinking/planning the implementation details of the stack. One of them is:
What things do we want to be efficient and what are we comfortable compromising for the stack to be maintainable?
Efficiency here speaks to how efficiently the system executes. Maintainability here speaks to the teams ability to keep it running.
I suspect that efficiency often times (if not always) comes at a cost of less-maintainable solutions by virtue of adding complexity to cater for non-functional things like performance and scalability or solving complex domain problems. Examples on the non-functional side include adding caching to increase speed, or at an even lower level, using something like memoization to reduce a computationally rigorous piece of logic.
If you agree with the above, the corollary is that designing specifically for maintainability could result in compromised efficiency. If you don’t agree, I’m always open to a socratic debate on it, but I’m going to work under the assumption of the former scenario.
I am of the opinion that a “maintainable” solution and an “efficient” one are contrasting. Finding the right balance between the two is one of my personal goals when I assist with designing/”solutioning” software.
A Personal Glossary of Theoretical Relationships around Maintainability and Efficiency
I have a few ‘theoretical relationships’ that I like to think about and use when in design conversations but before we get into it, I need to note a few definitions to make my life easier:
Maintainability Factor (m) - a quantitative measure that denotes how maintainable something is.
This can be subjective, or an effort could be made to create an objective measurement of this, but that’s going to be “de-scoped” in this read cause I don’t feel like doing that today6.
‘Distant’ is used to mean that something is not immediately reachable from wherever you are at that time.
An example of “distance” is if you have a BFF service and a corresponding frontend application, these two units are distant from each other.
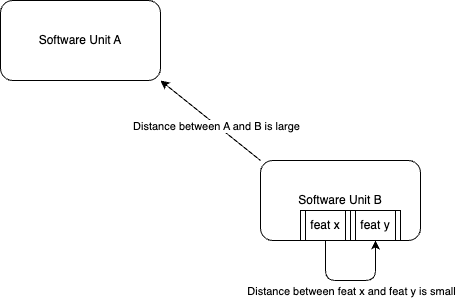
Theoretical Relationship A - Maintainability vs Complexity
The more complex a solution, the less maintainable it is over time.
I feel like this might be obvious, but for the sake of brevity…the more complex a solution is, the more knowledge about its mechanism is required. This could be domain knowledge, knowledge about how a particular technology works or even something as simple as the “why”, i.e. situational knowledge gained by being there when the decision to do something a particular way was made.
For the more mathematically inclined, this is an inverse relationship and here is the formula using what I like to refer to as my own brand of pseudo-mathematical notation8:
\[m = \frac{1}{complexity}\]Theoretical Relationship B - Number of Units vs Change Frequency
This is pretty straight-forward:
The more related units of ‘distant’ software you have, the more complex it becomes to maintain it.
If you have related software that necessitates frequent change, the multiplicity of effort to enact that change is inversely proportional to the maintainability factor.
Basically, having two BFF’s that you need to update is going to be more work then having a monolithic-esque MVC setup. We know that the front-office applications have a relatively higher frequency of change. This is a good example where you might want to compromise on the maintainability factor in favor of the non-functional, i.e. having BFF’s and following that pattern4.
Pseudo-mathematically:
\[m = \frac{1}{\sum units*frequency\ of\ change}\]Theoretical Relationship C - Complexity vs Number of Units
This is a bit more abstract. I’ve observed that in my lived-experience:
The more complex each individual unit, the less units you tend to have in total.
Not really sure how to reword this so instead I’m just going to make a haphazard attempt at an example.
If you design a complex function that caters for multiple scenarios, you have increased the complexity of an individual unit and decreased the need for multiple functions.
In pseudo-math:
\[\sum units = \frac{1}{complexity\ per\ unit}\]Theoretical Relationship D - Efficiency vs Complexity
This is arguably even more abstract:
Efficient solutions tend to be more complex
Note that this is drastically different from saying that complex solutions are always more efficient. Which I am not saying.
I’ve just found that the more efficient you make something, the more complex the overall solution. A perfect example is caching from earlier in this read. I’m sure many, many, many engineers can relate, but caching has been both a nightmare to maintain and a blessing to the client experience (but maybe not always at the same moment in time).
As an aside, a much smarter individual9 than me said: “There are only two hard things in Computer Science: cache invalidation and naming things”, and yet we still use caching because it’s useful. This speaks to a journey I often see in my more junior peers where they oscillate in the beginning from wanting to create complex and elegant solutions, to hyper simplified solutions that are really maintainable, before finally finding peace in the balance. But I digress…
In pseudo-mathematical fashion:
\[efficiency = k*complexity\]Theory - Efficiency vs Maintainability (coming full circle)
From Relationship A and Relationship D we get a theory:
If we hold that efficiency is proportionate to complexity and maintainability is inversely proportionate to complexity, then efficiency is inversely proportional to maintainability.
Remember that this works under the assumption that efficiency leads to complexity. Which I believe in, but you may not. Even so, however, the relationships above might prove useful for other things while this theory itself is not really that useful for much4.
Enter Pseudo-Geometry - Rishi’s Ideal Cone of Software3
A cone is this:

Now that we’ve gotten that out of the way. I combine all these pseudo-formulas above into a delightful4 little ice-cream cone that helps you make otherwise hard decisions5.
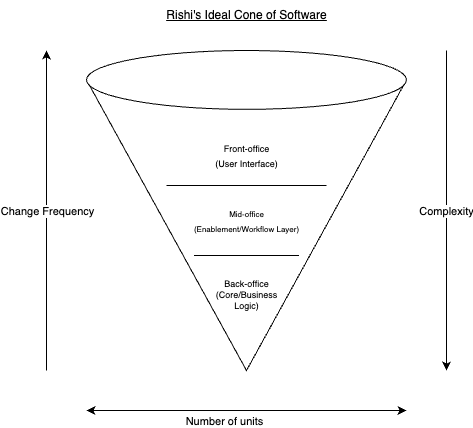
Following this mechanism, we get the following rules of thumb:
- More frequently changing software should probably be implemented in a less complex way
- Having less complex units probably means that you will be having more of them, which means you’d probably have more segmented or “distant” units the closer you get to your front-office. (This feeds in nicely to a different rule of thumb I use (for better or for worse) that frontends should be as dumb as possible, but I digress)
- You’d want more efficiency at your core, which likely means you have leeway to draft more complex solutions in your back-office to keep your operation (in the mid-office) running smoothly and efficiently
TL;DR
Using the mechanism of the “Ideal cone of software” could help provide rules of thumb when making decisions on how much to invest in making things efficient while allowing the right things in your software stack to be maintainable for the next engineer/team after you/yours moves on to the next stack.
- FIN -
Asides and References
- a ‘rule-of-thumb’ is defined as “a practical and approximate way of doing or measuring something” by Cambridge Dictionary.
- hopefully I am maturing, but is there really ever any way of knowing that are?
- no, you’re thinking of “cones of dunshire”…
- in my opinion…
- because everything is better with dessert…
- look at me channeling my inner project manager…lol
- I wonder if this is wisdom or trauma.
- This is “pseudo” because I don’t claim to be a mathematician and I don’t want people that do to come after me. They happen to be pretty smart so they’d probably find a way
- Phil Karlton